The website is revamped with a new theme (Portfolio Press). The original blogs are available in the Blogs section.
Protected: iFaceDQ (2021)
Hong Kong Wall Paintings (2020)
This is a collection of photographs I took on various locations in Hong Kong where different institutions used colour paint and other means to cover or remove the graffiti, signs and slogans. Most of them were left over from the protests in 2019.































Protected: National Anthem (2020)
Movement in Time, Part 2, live version (2020)
The live version of Movement in Time, Part 2 was proposed to an exhibition originally scheduled to show in Shenzhen in mid 2020. Owing to the covid-19 situation, the exhibition was postponed without any new schedule yet.
The work is a modified version of the original Movement in Time, Part 2. Instead of using existing martial film fighting sequences, the live version will employ a camera to capture the movement of the visitors to generate the cursive style Chinese calligraphic characters.




The first approach made use of a regular webcam to capture the optical flow of the visitor’s movement.
The second approach made use of a depth camera (Primesense) to capture the skeleton movement to identify the closest matched Chinese character.
Movement in Time, Part 2, Red Temple version (2019)
Hong Kong in Poor Images
This is a re-run of the original Movement in Time, Part 2 artwork with 2 new fighting scenes from the 2 martial art films with the same Chinese title 火燒紅蓮寺.
- The Burning of the Red Lotus Temple 1963
- Burning Paradise 1994
It is created for an exhibition Hong Kong in Poor Images (curated by Hong Zeng) shown in the Ely Center of Contemporary Art, New Haven, 12 Jan – 16 Feb 2020 .
The Movement in Time series explore the creative use of movement/motion data obtained from found footages of motion pictures. The Part 2 series investigate the motion data from the fighting sequences of martial art films from Hong Kong, Taiwan and China. Once the motion data is extracted from different scenes, it is matched against a database of cursive style Chinese calligraphic characters known as the One Thousand Characters Classics 千字文. The actual matching is based on machine learning algorithms. The matched Chinese characters will be shown on the screen as animated writings. This version also gathers all the matched characters into poetic lines. These lines are, however, not sensible to read as real poem.
In order to obtain the movement/motion data, the custom software that I developed makes use of the technique known as optical flow, in computer vision. It basically tracks the flow of pixels across consecutive picture frames in time. The visualisation of optical flow resembles a low resolution image digitised in poor quality. Nevertheless, it is just low-res enough to give viewer a sense of what the motion is.



Post exhibition development
After the exhibition in Yale, I reworked the software with the same film clip from The Burning of the Red Lotus Temple, with different approaches. Here are some of the experiments. The final artwork may show in a coming exhibition in Shenzhen in July 2020.





Protected: Be a Hong Kong Patriot, Part 3, The Red Scout (2019)
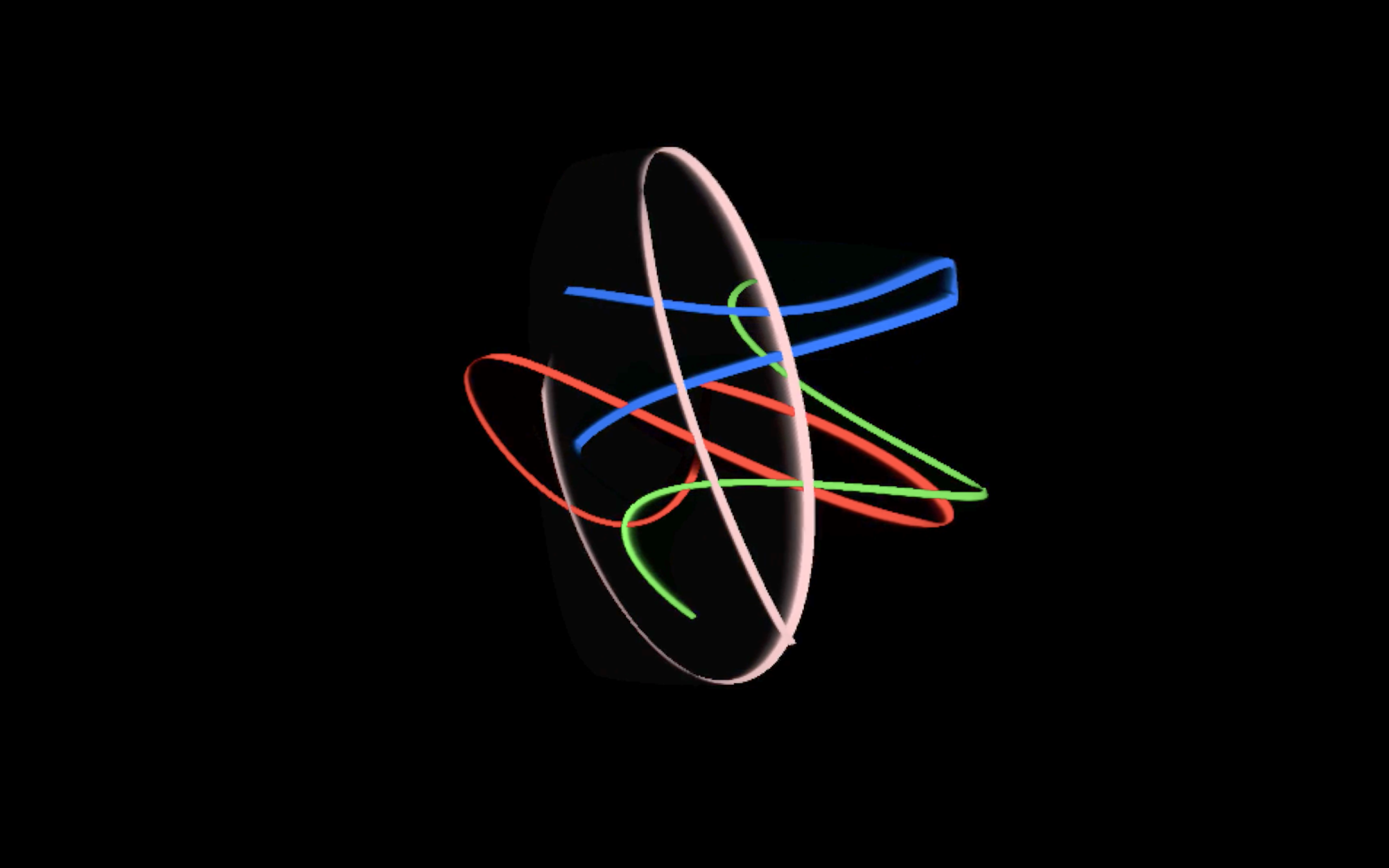
Movement in Space, Part 2 (2018)
Movement in Space, Part 2 is an interactive installation with maximum 4 participants controlling 4 sets of animated graphics generated from harmonic motion, and shown through a hologram display. Each animated graphics can influence each other with connection and dis-connection of physical cables.
The artwork is part of the Algorithmic Art: Shuffling Space & Time exhibition in Hong Kong City Hall from 27 Dec 2018 to 10 Jan 2019. The exhibition is one of the public event from the Art Machines: International Symposium of Computational Media Art that took place from 4-7 Jan 2019 at the School of Creative Media, City University of Hong Kong. Movement in Time, Part 2 has been invited to join the exhibition as one of the local participants showcasing the concept of algorithmic art.




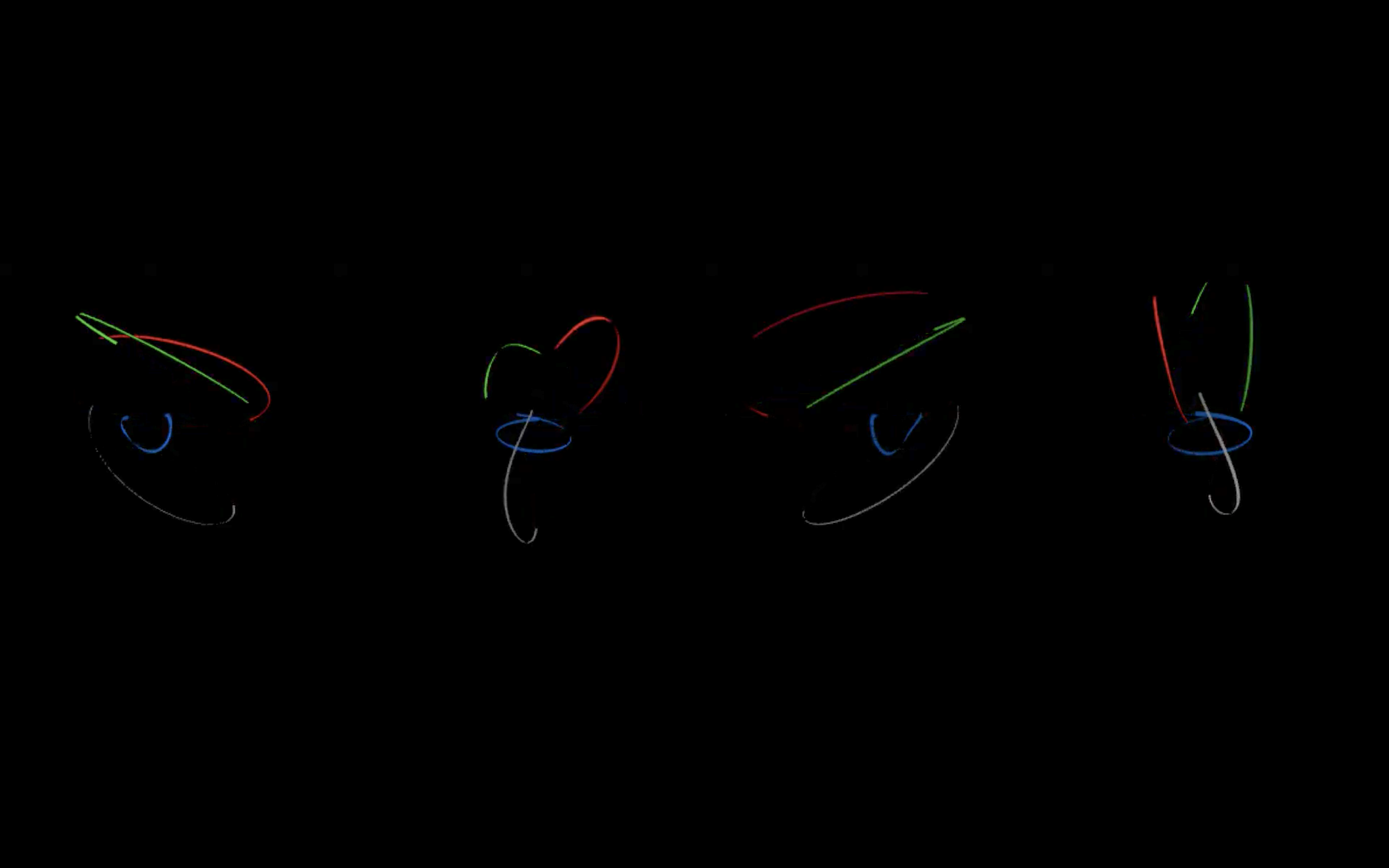



Exhibition view at the Hong Kong City Hall




Part 2 is an extension of the original web version of Movement in Space. It also built on top of the implementation of harmonograph by pure software, without the hardware details of the construction of pendulum.

The custom software was built in Processing around the ideas of concatenating sequences of trigonometric functions such as sine and cosine. The imageries may resemble the early computer art and oscilloscope art, such as the works from Ben Laposky.

It starts with the simple parametric formulae to draw an ellipse in 2 dimensional plane.
x = A x cos (t)
y = B x sin (t)where A, B are two numbers and t is the time step for animation. It was then extended to 3 dimensional space with more parameters for more sophisticated control.
x = A x cos (B x t) + C x sin (t + D)
y = E x sin (F x t) + G x cos (t + H)
z = I x cos (J x t) x sin (K x t + L)where A, B, C, D, E, F, G, H, I, J, K and L are 12 numbers ranging from -1 to 1. By changing the 12 numbers, the software can generate very sophisticated drawings. In addition to this, the artwork consists of 4 drawing units. The outputs (x, y, z) of 1 drawing can redirect to the inputs (A – L) or another drawing unit, and which is a simplified version of an artificial neural network. In the installation, the 12 numbers are controlled by the iPad interface while the connection from one unit to another is done by physically plug in of a signal cable.

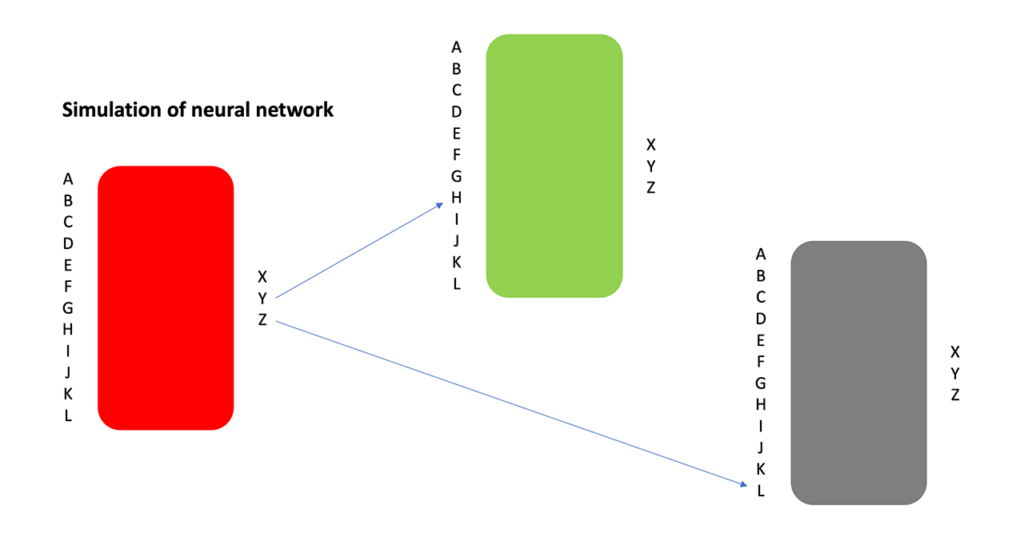
Each of the four units is equipped with physical sockets and cables to connect the outputs from one unit to the inputs of another.




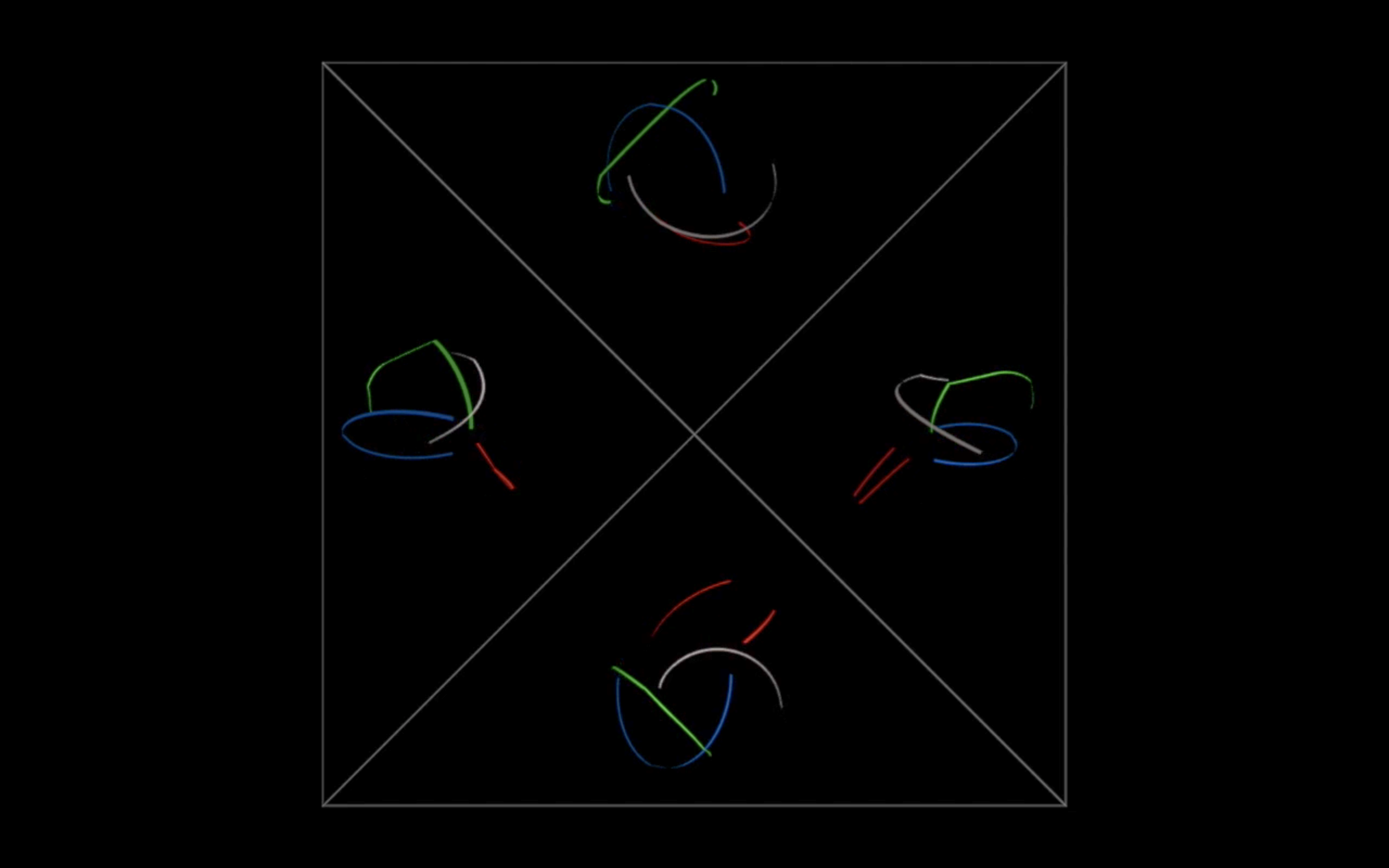
The video below is a simulation of the 4 drawing units viewed from 4 directions (North, West, South and East). Each participant has his/her own color coded animated drawing.
It is a revolving version of the four animated drawings in the 3 dimensional space.
The video below is a software simulation of the hologram display of the four directions.
Video documentation of the artwork exhibited in the City Hall
Movement in Time, Part 2 (2016)
Chinese martial art film fighting sequence and Cursive style calligraphy
Background
The artwork is the second part of the Movement in Time series. Part 1 used 100 popular Hollywood film sequences to generate animated action paintings. Part 2 of the project analysed the fighting sequences in traditional Chinese martial art films. The results will match against the brush stroke data from the famous Cursive style Chinese calligraphy text – the One Thousand Characters Classics 千字文. In the end, the fight sequences will automatically generate a piece of unique text from the character database. Part of the project is funded by the Faculty Research Grant from the Hong Kong Baptist University.
The Cursive style Chinese calligraphy
In Tang Dynasty, there was a legendary story about the famous Chinese calligrapher, Zhang Xu 張旭. When he was drunk as usual, he saw a sword dance performed by the madam Gong Sun 公孫大娘. Since then, he was inspired to create the Wild Cursive style in Chinese calligraphy. It was the first motivation that I tried to use digital media to connect these two different types of traditional Chinese art forms, calligraphy and martial art.

With the help from a former student, Ms. Lisa LAM, I digitised all the 1,000 Chinese characters using a drawing tablet with a customer program developed in Processing. Each character will have a separate XML file to keep the brush stroke information. Here is a sample of an XML file.
<character>
<stroke time="0">
<point>
<x>0.21666667</x>
<y>0.395</y>
<w>0.032258064</w>
<t>5</t>
</point>
<point>
<x>0.21666667</x>
<y>0.39666668</y>
<w>0.121212125</w>
<t>33</t>
</point>Given the XML file, I can recreate each Chinese character either in still image or animation.
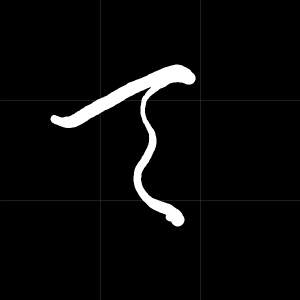

Given the touch/pressure sensitivity of the drawing tablet, I can simulate the depth information in 3D. It introduces an additional stylistic rendering of the Chinese characters in three dimensional space. Here are some experiments with 3D rendering of the Chinese characters.
The Chinese martial art films
The second component of the project is a collection of the famous Chinese martial art films. I studied and digitised a number of Chinese martial art films from director ranging from the traditional King Hu to the more contemporary Ang Lee.
I developed a custom software, in Processing and OpenCV, to use different methods of motion analysis to extract motion data from the fighting sequences. By experimenting with the motion data as virtual forces, I managed to animate a piece of string (thread) dancing across the screen.
Here are some examples of using the OpenCV functions, such as motion history, dense optical flow to analyse the fighting sequences from the films: Hero (2002), Seven Swords (2005) and Crouching Tiger, Hidden Dragon (2000).
Representation of the 1000 characters
Given the 1000 XML files of the one thousand Chinese characters and some mechanisms to extract fighting data from the martial art film sequences, I have to find a way to enable matching between them. In this case, I go back to my experience of learning Chinese calligraphy. In my childhood, like other kids, I learnt Chinese calligraphy by copying the grand masters’ works with the aids of a grid chart. Normally, we use a 3 x 3 grid chart to layout the brush strokes of each character. In the testings, I have used different grid sizes such as 3 x 3, 5 x 5, and 9 x 9.
With the 1000 Cursive style Chinese calligraphic characters, I also explore different ways to represent them in terms of point density, stroke direction, etc. The results will lead to different ways to enhance matching from the encoded fighting sequence to a unique Chinese characters. Here are some testing results to represent each of the Cursive style characters in a 9 x 9 grid, using both point density and stroke direction, respectively.
Point density model
Stroke direction model
Character representation models


Matching the fighting sequence and characters
In this phase, I explored the machine learning library from OpenCV and the Weka Machine Learning library to test run the matching against a fighting sequence and a Cursive style character from the database. Before I started matching with the fighting sequences, I developed another testing software to cross match a live character writing exercise with the 1000 characters in the database, using both the OpenCV machine learning library and the Weka library, with the K-nearest Neighbour matching.
Exhibitions
In November 2016, I was invited to participate in the Japan Media Arts Festival, Hong Kong Special Exhibition in The Annex, Hong Kong. The artwork includes four martial art film sequences, Crouching Tiger, Hidden Dragon, Hero, House of Flying Daggers (2004).
It is a computational animation where a custom software written in Processing executes live to extract motion data from the film sequences and match in real time with the 1000 characters in the database. The closest match one will be drawn on the fly in the screen. The display screen consists of 4 parts. The top left part is the original film sequence rendered in dense optical flow vectors. The bottom left part is the summary of all the optical flow data and reduced to a 5 x 5 grid indicating the most prominent movement on screen. In each frame of the playback, the motion data summarized in the 5 x 5 grid will match with the 1000 characters database. The closest matched character will be shown on the bottom right part of the screen animating the brush strokes of the characters. The top right part indicates where the current brush stroke position along with the path it travels in previous frames.
Recently, I enhance the work to accumulate all the characters matched successfully in the fighting sequence to form a piece of poetic text, on the top right corner of the screen. The order of the characters is determined purely by the fighting sequences. Quite obviously, they do not intend to make any senses. Nevertheless, when we continue to read along the characters stream, it appears like a poem and occasionally seems to carry meanings beyond our imaginations.
Source code
The artwork is released as open source material. The source codes can be found in the repository Movement in Time – Part 2